Interlock: A STAMP-Based Safety Framework for Data Pipelines
How I built a STAMP-based safety framework in Go with declarative sensors, failure classification, and centralized observability for data pipeline reliability on AWS
Read moreTechnical articles on data engineering, Apache Spark, Python, MLOps, and site reliability engineering by Dustin Smith.
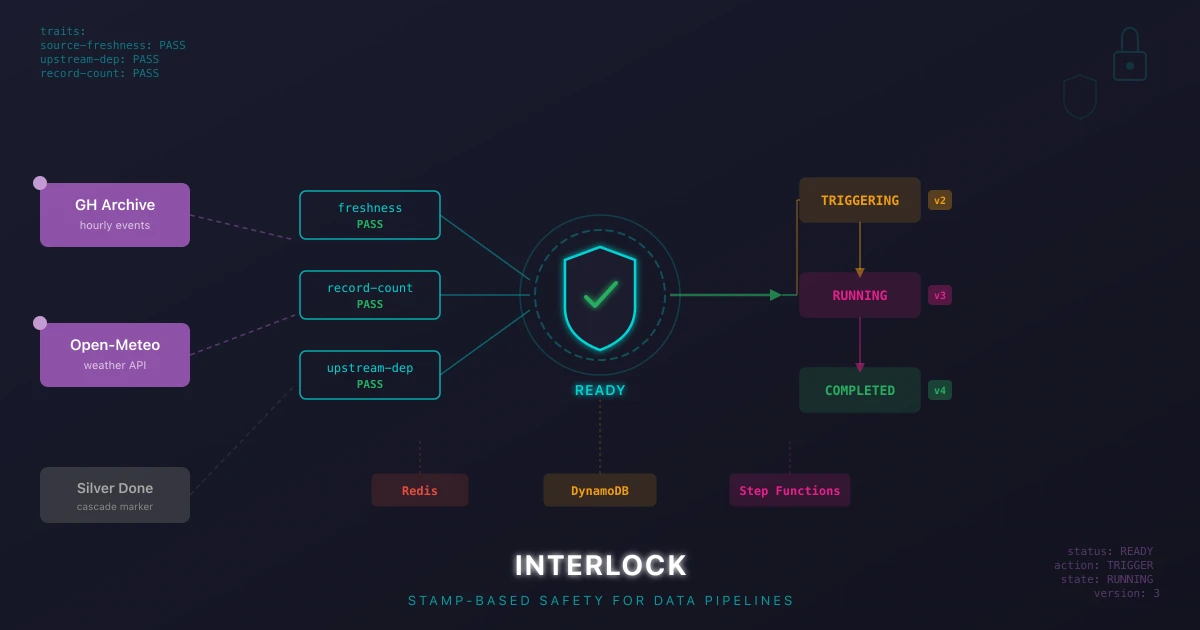
How I built a STAMP-based safety framework in Go with declarative sensors, failure classification, and centralized observability for data pipeline reliability on AWS
Read more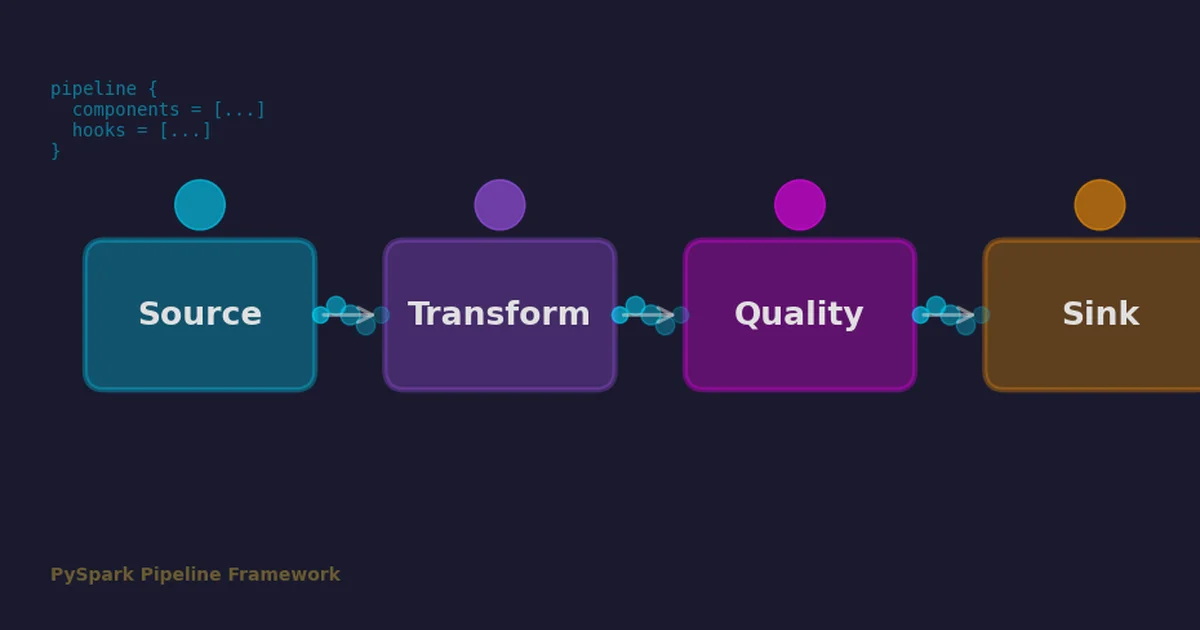
How pyspark-pipeline-framework brings configuration-driven architecture, lifecycle hooks, and resilience patterns to PySpark
Read more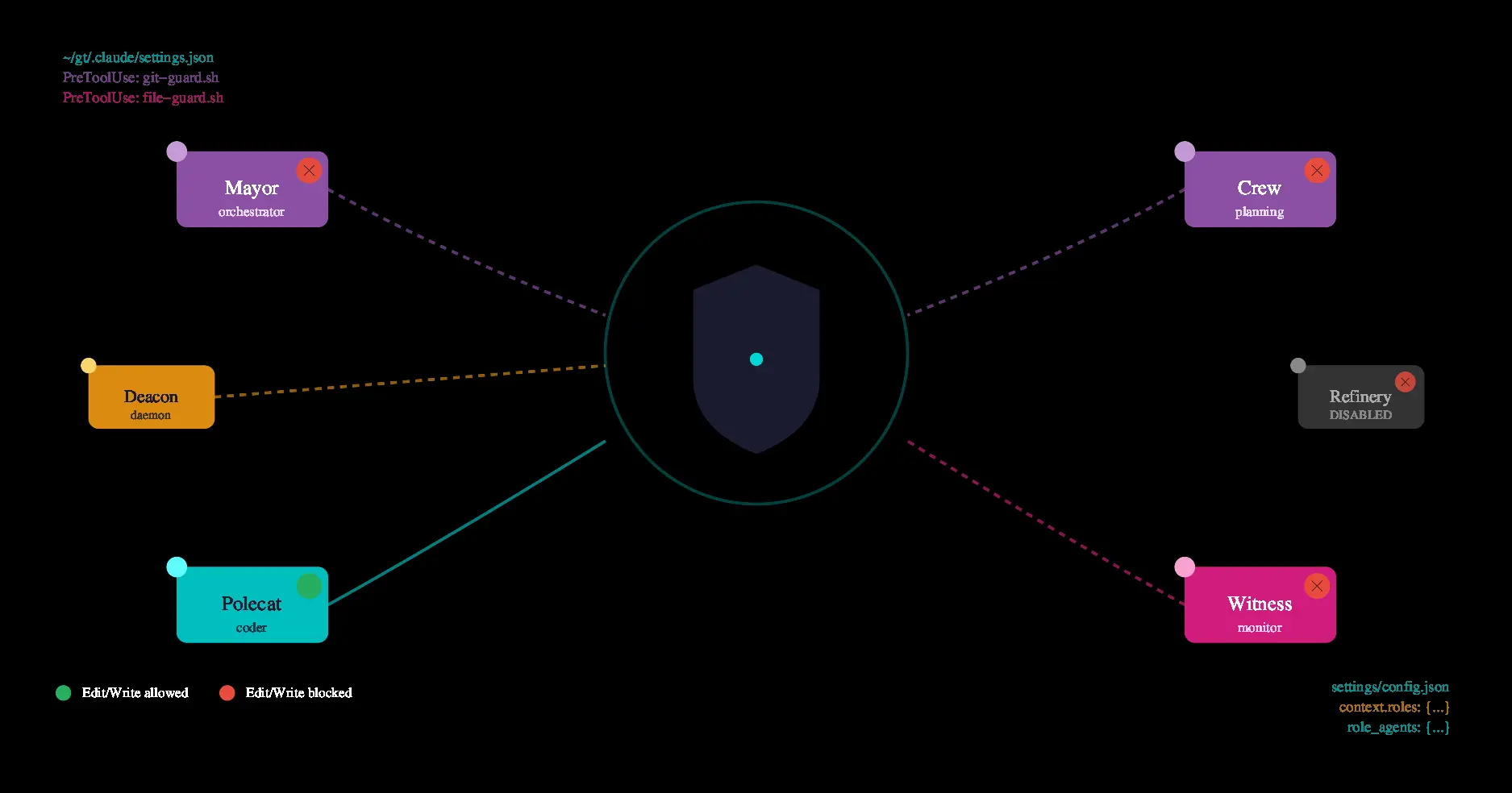
Configuring Gastown for production use with custom role contexts, Claude Code hooks, git guards, and file guards to enforce principle of least privilege across AI agents
Read more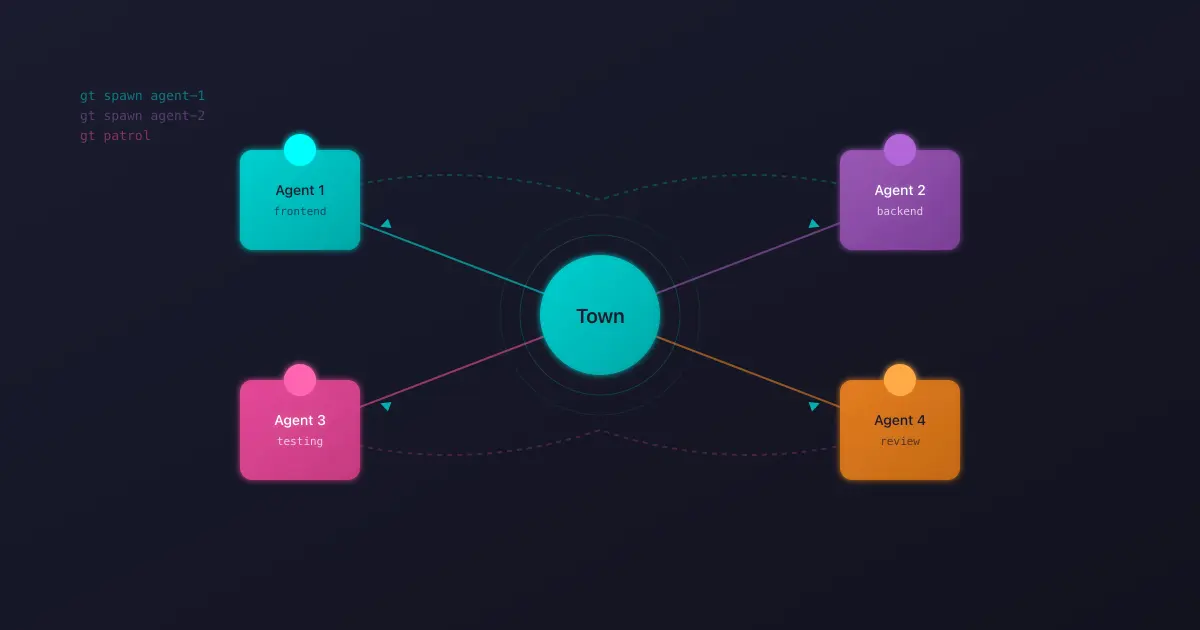
5 merged PRs and 8 open contributions to Gastown, covering daemon resilience, fresh installation fixes, and autonomous patrol improvements
Read more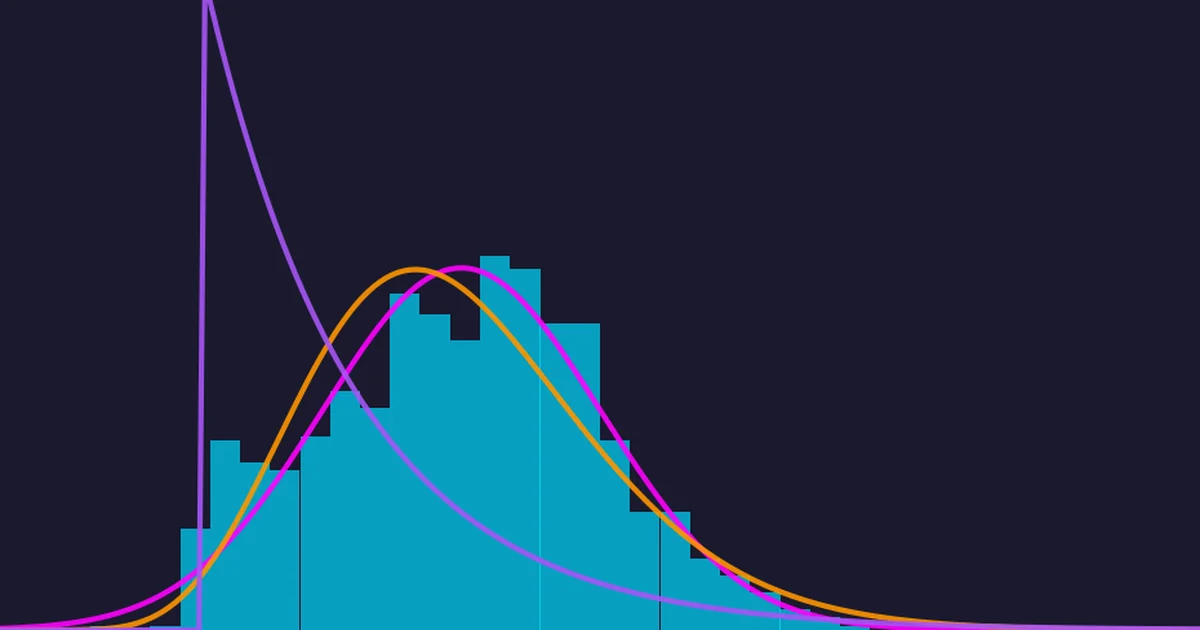
How spark-bestfit 3.0 fits distributions across Spark, Ray, and local backends with survival analysis, mixture models, and multivariate support
Read more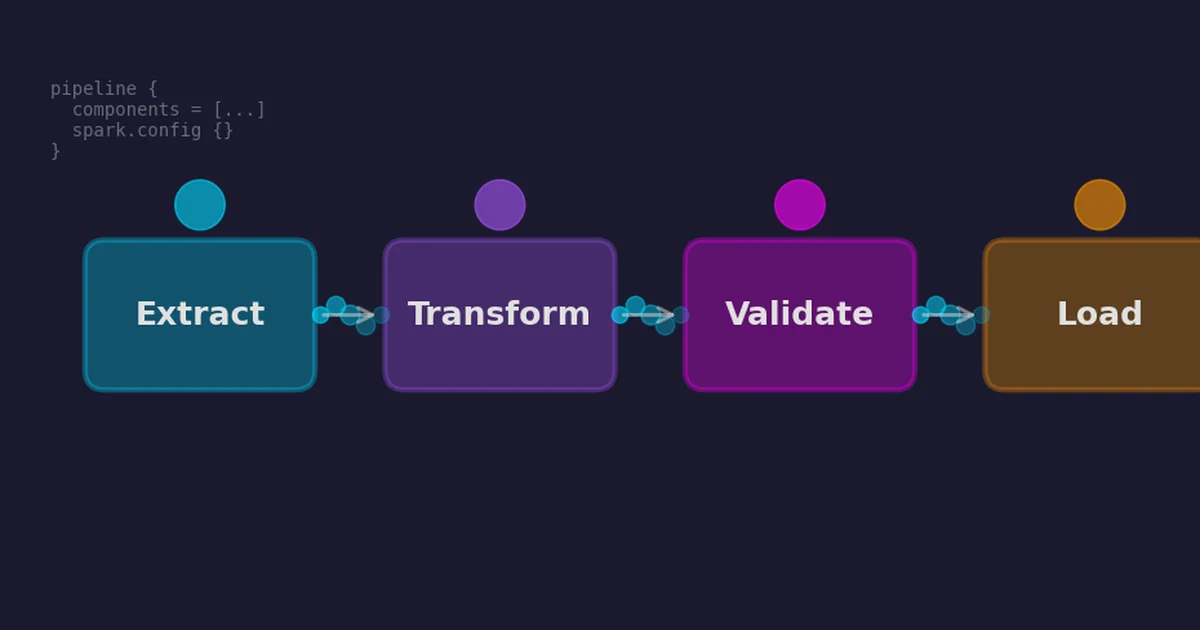
How spark-pipeline-framework reached 1.0 with Spark Connect support, streaming, and enterprise features
Read more
My experience from Delivery Hero's 2023 layoffs.
Read more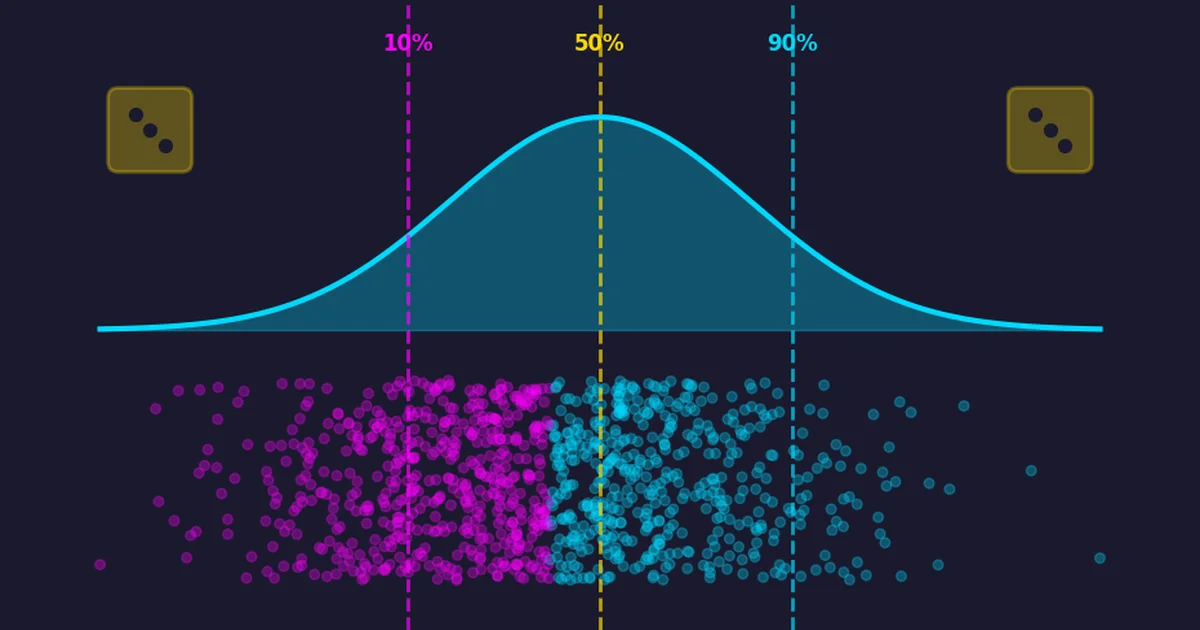
How to use Monte Carlo simulations in Python to make better capital investment decisions, with a practical example of evaluating cloud migration costs.
Read more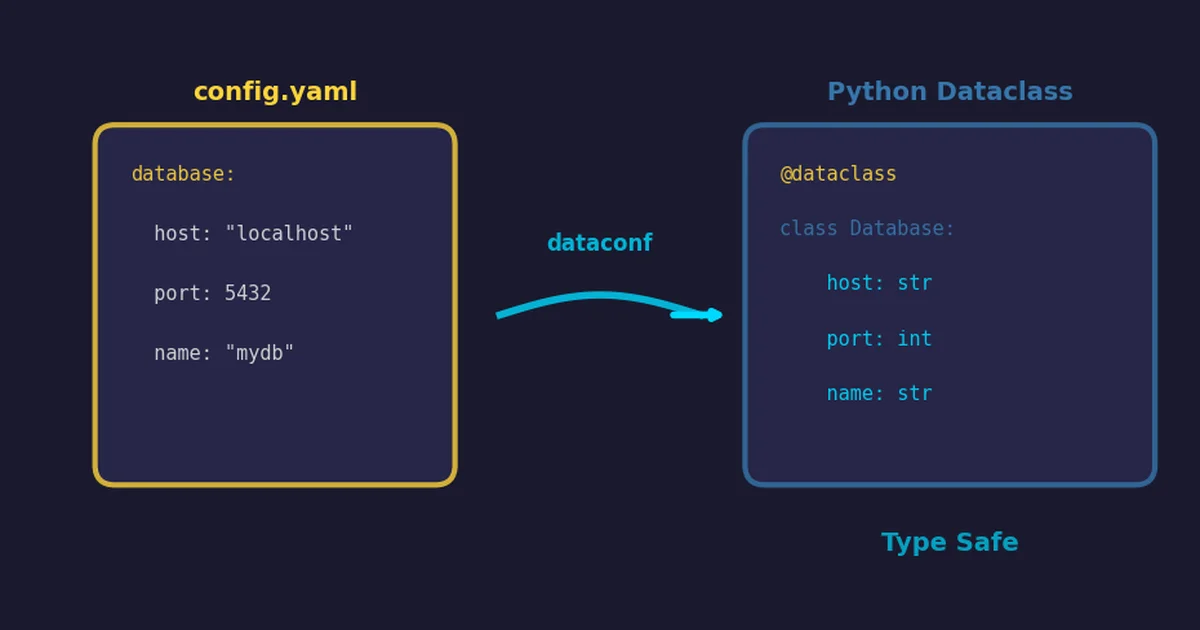
How to use the dataconf library to parse HOCON, JSON, YAML, and properties files directly into Python dataclasses with full type safety.
Read more
How intelligent data optimization with linear ordering and Z-ordering achieved 77% storage reduction and 90% runtime improvements on petabyte-scale data lakes.
Read more