Interlock: A STAMP-Based Safety Framework for Data Pipelines
How I built a STAMP-based safety framework in Go with declarative sensors, failure classification, and centralized observability for data pipeline reliability on AWS
Read more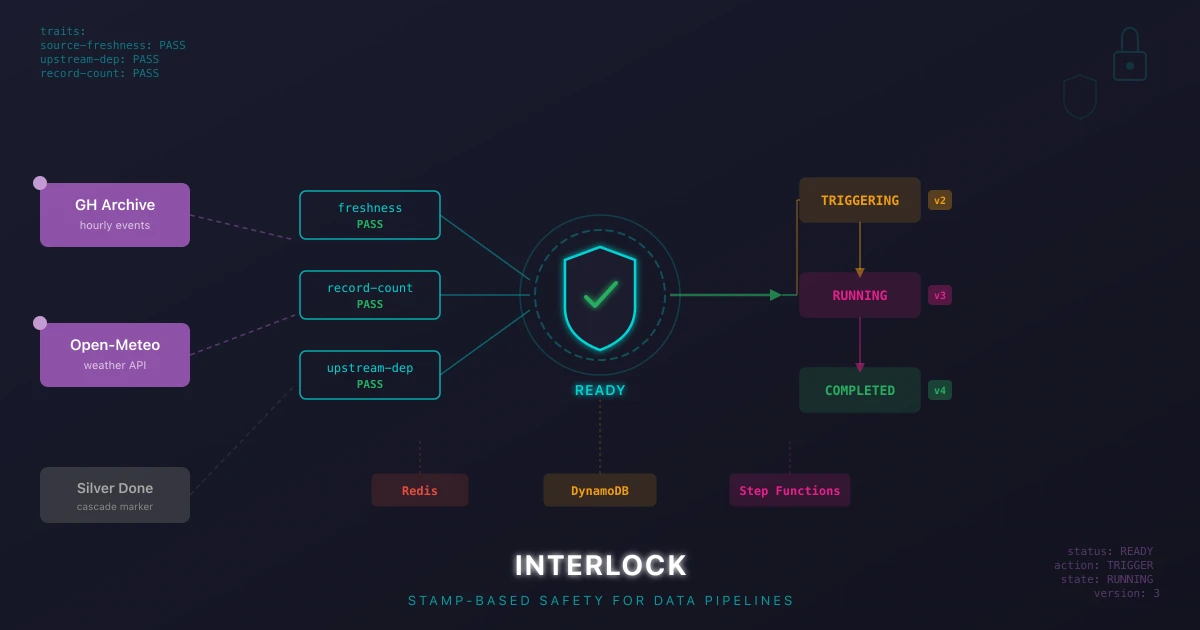
How I built a STAMP-based safety framework in Go with declarative sensors, failure classification, and centralized observability for data pipeline reliability on AWS
Read more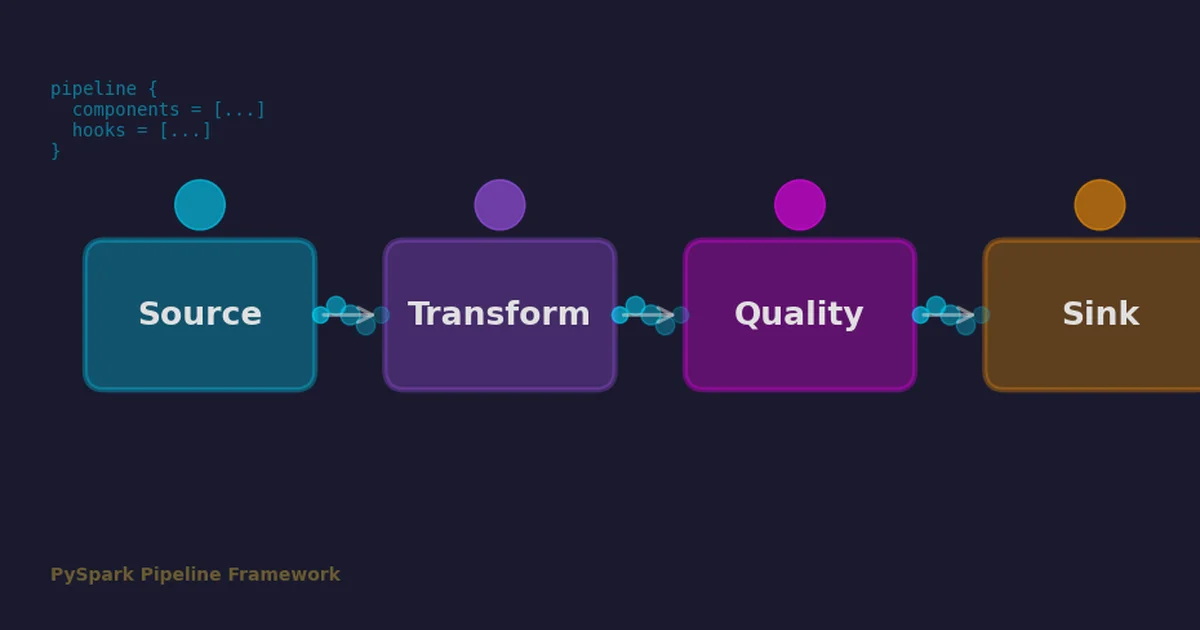
How pyspark-pipeline-framework brings configuration-driven architecture, lifecycle hooks, and resilience patterns to PySpark
Read more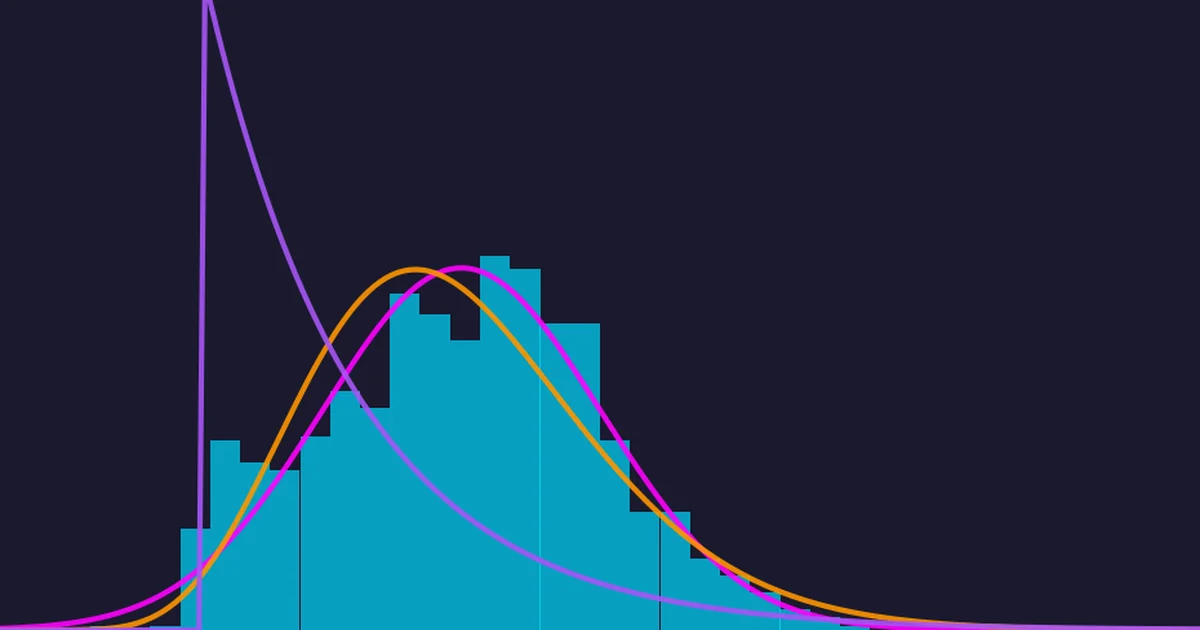
How spark-bestfit 3.0 fits distributions across Spark, Ray, and local backends with survival analysis, mixture models, and multivariate support
Read more
How spark-pipeline-framework reached 1.0 with Spark Connect support, streaming, and enterprise features
Read more
How intelligent data optimization with linear ordering and Z-ordering achieved 77% storage reduction and 90% runtime improvements on petabyte-scale data lakes.
Read more