Fitting 100 Statistical Distributions at Scale: 1000x Memory Reduction with PySpark
How spark-bestfit 3.0 fits distributions across Spark, Ray, and local backends with survival analysis, mixture models, and multivariate support
Read more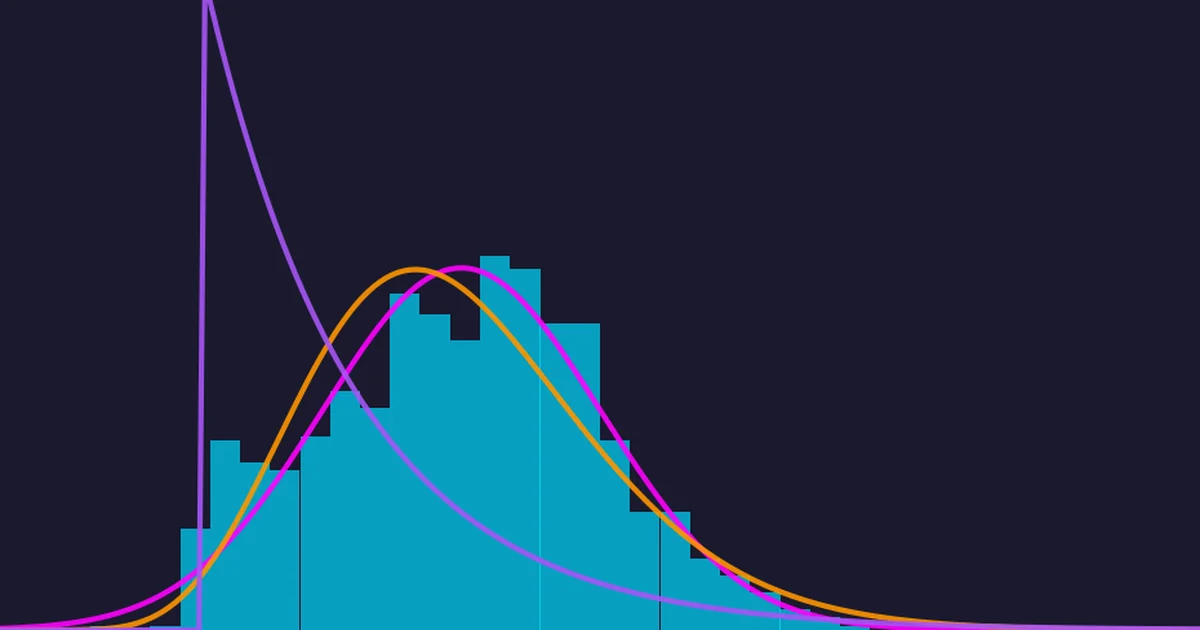
How spark-bestfit 3.0 fits distributions across Spark, Ray, and local backends with survival analysis, mixture models, and multivariate support
Read more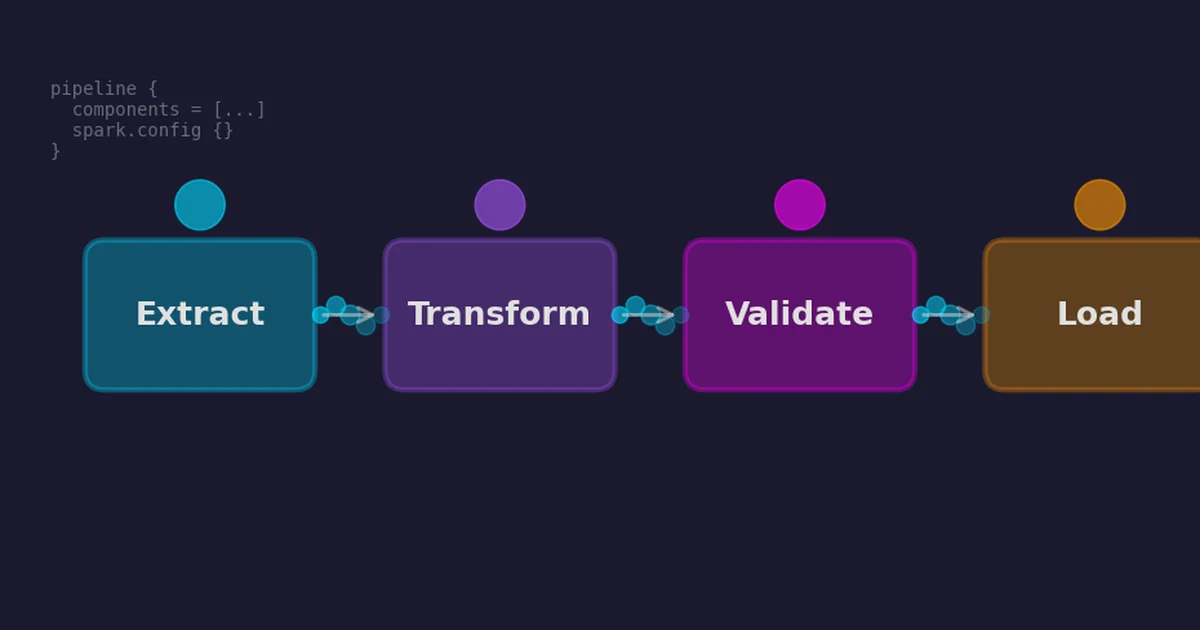
How spark-pipeline-framework reached 1.0 with Spark Connect support, streaming, and enterprise features
Read more